I am in Web 2.0 ignorance recovery. For two months I’ve been playing catch-up about web 2.0 and social software. If I say something stupid or ask questions already answered please just comment me a link and I’ll shut up. (If you’re new too, start here).
Some folks have criticized blogs for being an echo-chamber: meaning that many blogs simply echo each other and people debate within narrow boundries. I’m not making this point, but I am leapfrogging over any echo debates to ask a larger question.
del.icio.us is a canonical example of both social software and Web 2.0. Simply put: in this example of social software (SS) people mark items that interest them and people can view the results. Looking at the top marks, it reflects a curious bias. Take a look:
Exhibit A: the most recent list of most popular del.icio.us items.
Generalizing from top ten lists has many downsides, given long tails and power laws, but it is an easy catalyst for questions.
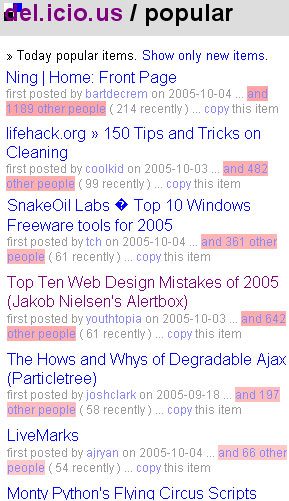
This list seems not like what’s popular with most of the people I know, but what’s popular with the Computer science / web development/ blogging crowd (some of the people I know). Ajax is a development tool. Ning, the highest ranked item on the list, is a new kind of social software development platform. Half of the top ten are items reflect the kinds of things the makers of delicious are likely interested in (I mean come on: Monty python is just a dead give away. Although the cleaning link made me consider a programmer/OCD connection). This popularity snapshot expresses an interesting kind of bias: the users of this social software reflect the interests of the makers of the social software. I suspect the majority of delicious users, today, have similiar interests to the makers of delicious.
Exhibit B: Popular delicious tags
Tagging, which is another key aspect of social software, also makes visible some interesting bias effects.

The most popular tags again reflect the interest of people who make the tools. Web 2.0 and social software is new enough that the early adopters are not just super interested users, but tool builders themselves (See this for more tags). I am not suggesting why this happens, just making the observation that it may be true.
Exhibit C: Popular 43things.com tags
At another social software project, 43things.com, there’s a broader distribution:

Here are my questions:
1) Why does one social tagging system have such a different kind of focus (delicious) while the other doesn’t? Delicious and 43things are both available to the world. What explans the wide gap in their user’s interests? How do the demographics for Flickr.com, a service believed to be consumer oriented but which many of my thirty something friends have never heard of, compare to other kinds of tools? Other kinds of social software? Are they younger? More affluent? Are there generation gaps tied to social software?
2) In using friendster, linked-in, orkut and other social networking tools, I had the experience of meeting the same people in different systems. It was like being in college and moving the party from building to building (only without the drugs. Well, at least on the networks I was invited onto). Did I just not know enough people? Or is the social software crowd, today, smaller than we admit? Is anyone examining if diversity is growing with size?
3) What are the risks of the frameworks for social software being defined so strongly by early adopters? Do the frontier settlers self-interest, and ability to define their world, restrict the kinds of followers than will come (I think so)? (Insert favorite Mcluhanreference here)
4) How does a user new to a social software project establish a sense for how his interest match with the popular interests of the most active users? Where are the the tools that let me search against delicious like data to see what’s popular with people who have traits or interests I care about? For example: there will never be a luddite group on meetup.com. What other hidden biases are there? The digital divide as an important but easy example, but there are more subtle ones.
5) Are there inherent biases that most active users in social software have (e.g. technical, high math SAT scores, etc.)? How does this impact how social software should be designed? A traditional software designer can shape the design around different, and possibly under-represented, user’s needs – but if social software is user driven what counterbalances are there?
6) Are the things that interest social software early adopters the same things that will interest more mainstream and diverse people? Should anyone care?







{kind=link}